Using a Markov Chain to impersonate people

For this hackathon, my goal was to learn and implement a type of machine learning method in a fun way. I googled around and found several blog posts for building Slack bots with Markov Chains, they all looked pretty simple so I set off my journey to build my own Slack bot using the Slack messages that are available to me.
I started my project based on an inspiring blog posted by Lofty Labs, however, the Slack implentation described in the blog post was outdated (Slack completely rewrote the slackclient library and the custom integration was deprecated and no longer available ) and the settings of the bot confirguration was not explained in detail.
The first thing I did was create a bot on Slack and gave it permission to access all info about my public channels and read my Slack public channel history, this way the bot is able to read about past messages and listen to real-time messages from all the public channels. One can actually test the permission of the bot before adding a particular permission, this is important becuase the permission you are thinking of might not be the right one. When a bot is generated, a token (think of this as a secret code Slack uses to identify an object) was generated as well. This token allows the bot to communicate with Slack Platform’s RTM API where one can use script to program the bot. Since the bot comes with the permission to post message on Slack channels as a memeber, using only the bot token is enough to complete the project (no need to generate token of the user). The next fun part was to store all the messages I would need to impersonate someone. I started with getting one co-worker’s message history and further extended to store message histories of all team members and all channels, where I would have the ability to impersonate anyone or any particular channel. The post from Lofty Labs provided a good implementation of the basic functions needed for calling the main function, which can be easily adapted to more complicated usage (retriving and saving to different databases, using different trigger words for channel-specific or person-specific impersonation, and updating databases while listening to real-time messages). One remaining challenge is to transform existing code from the blog post to a format that would work for me, this can be confusing since there is a major change in the key library of the Slack bot, which changed the way of connecting to Slack, querying message of a particular person/channel and posting messages. These tasks all seems to be related to real-time message API but the links between old platform and new platforms are not well-documented (e.g only sparse examples are given without explicitly explaining the attributes of the library).
After getting each piece to work, I started testing my bot by talking to it using trigger words I specified in the program. So far I only found ways to query a maximum of 1000 messages per channel, which is not ideal for impersonation of a person who is quiet recently (since there is not enough data to make a stable model). I first tried Markov Chain using a well-developed package Markovify, it worked amazingly well using the default setting (state_size =2). After understanding the idea behind Markov Chain (Ref1, Ref2), I started writing my own Markov Chain script with the logic that the occurance of a future word (state) only depends on the current word (state) rather than the previous word (state). We can record all unique words appeared in a text corpus, and generate probability of the next word given the frequency of the occurances of that particular word following the current word. The begining of the sentence would be draw randomly from a list full of first words in a text corpus and the sentence would stop once the current word matches to any words from a list of ending words.
Comparing the result of my vanilla Markov Chain to Markovify package, on average the vanilla version is generating shorter sentences while Markovify package generates more phrases and sentences from the original text. This difference might be due to the different state sizes of the Markov Chains, as my vanilla package always uses each word as a state while Markovify is optimized to use several words as a state.
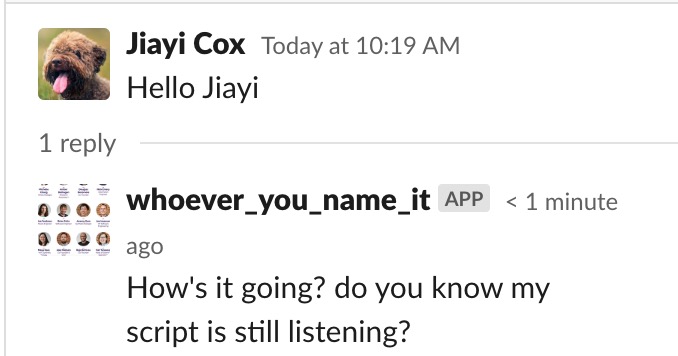
Here are the comparison when asking the bot to talk like me:
Using Markovify package:
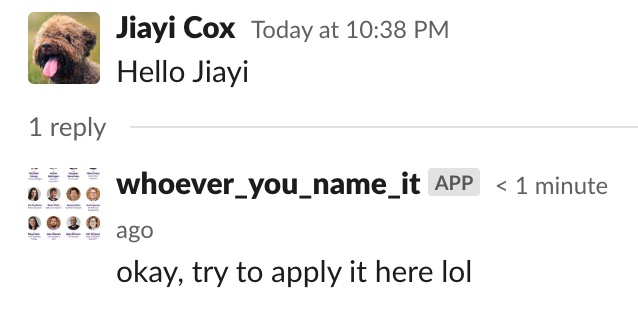
Using my vanilla package:
The code of this project can be found on my Github.